Speech Synthesis Becomes More Humanlike
Researchers from Google and the University of California at Berkeley have published a new technical paper on the Tacotron 2 neural network for speech synthesis. The results are impressive. I suspect many people have noticed that synthetic voices have improved greatly over the past two years and even made advances this year. Google Assistant is notable example. The latest research is highlighted in a paper titled, Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions. The report summarizes the results:
Our model achieves a mean opinion score (MOS) of 4.53 comparable to a MOS of 4.58 for professionally recorded speech…WaveNet, a generative model of time domain waveforms, produces audio fidelity that begins to rival that of real human speech and is already used in some complete TTS systems.
Improving Prosody to Sound More Humanlike
The prosody is key. Prosody is the intonation, stress and rhythm that makes human speech more than just consonant and vowel phonetics. For example, Tacotron 2 automatically changed the stress and tone when expressing similar sentences where one was a statement and the other a question.
“The quick brown fox jumps over the lazy dog.”
“Does the quick brown fox jump over the lazy dog?”
Can You Tell Which is Human and Which is AI?
The study results also provided some examples of both recorded human voice and AI-generated speech. Can you tell the difference?
“That girl did a video about Star Wars lipstick.”
“She earned a doctorate in sociology from Columbia University.”
You can listen to more examples of human versus AI comparison as well as some that point out the ability to correctly interpret appropriate stress and others that adjust the speech based on punctuation. It is worth noting that this is a system that learned on its own. The report concludes:
The resulting system synthesizes speech with Tacotron-level prosody and WaveNet-level audio quality. This system can be trained directly from data without relying on complex feature engineering, and achieves state-of-the-art sound quality close to that of natural human speech.
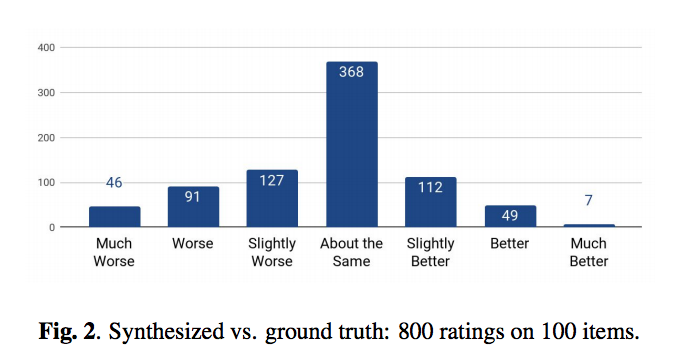
Humans Rated the AI vs Human Speech Fidelity
The system used “24.6 hours of speech from a single professional female speaker.” The results of the Tacotron 2 output was compared to the human speech (i.e. ground truth) to generate 800 ratings of 100 randomly selected speech samples. Human speech still wins, but not be very much. You can even see that many raters were fooled into thinking the AI speech was a human.
Speech Synthesis and Voice Assistants
It may be that the quality of AI-based speech synthesis is already good enough for most consumers. The rapid adoption of Amazon Alexa, Google Assistant, Cortana and even Siri suggest current issues with prosody are being ignored in favor of the convenience and utility provided by voice interaction with computing resources. However, the rapid improvement toward more humanlike speech should make the voice assistant user experience even more pleasant in the coming years.
Microsoft Hits New Conversational Speech Recognition Milestone
CIRP Says 27 Million Amazon Echo and Google Home Smart Speakers Sold