

Voicebot Interview with Todd Mozer of Sensory
 Todd Mozer is Chairman and CEO of Sensory Inc.
Todd Mozer is Chairman and CEO of Sensory Inc.
Sensory has been around for over 20 years. How have things changed for you? Did you start out in voice and voice recognition?
Todd Mozer: We started Sensory with the vision of doing embedded AI, with voice recognition as the initial focus and haven’t done any pivoting except to add vision, biometrics and more natural language. We did start with our own chips doing speech recognition. Our biggest change is we now are using other people’s hardware. What is interesting is that we started out doing neural network speech recognition. At the time that wasn’t very popular and now pretty much everyone is taking that approach.
How much of your business is dedicated to voice?
Mozer: About 95% of our revenue is dedicated to voice. However, we are putting a sizable investment into vision as well as into services to enable more convenient authentication and other capabilities.
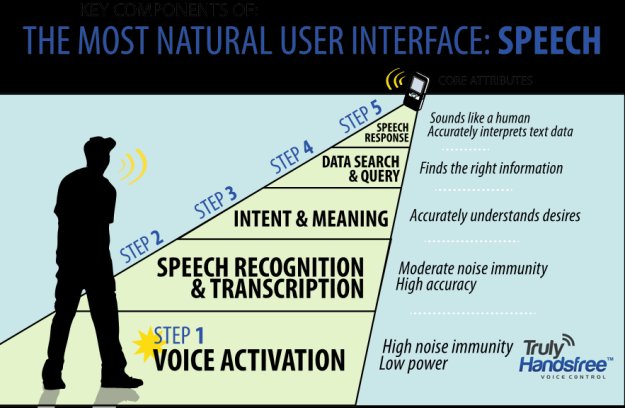
The TrulyNatural solution is a neural net speech engine that claims to have embedded architectures with scalable sizing. Does this mean you can put your speech engine only on a device or do you have a more compute intensive option that is cloud based?
Mozer: We can run it in the cloud, but our unique advantages are on the device. It has lower MIPS and is less resource intensive. We have the least battery intensive uses of speech recognition in our TrulyHandsfree line, where we can run on about 1 mA. TrulyHandsfree and TrulyNatural are embedded deep learning neural net speech recognition for devices.
 I saw the VoiceGenie announcement from CES. How is that different from products you have produced previously?
I saw the VoiceGenie announcement from CES. How is that different from products you have produced previously?
Mozer: We have been in the Bluetooth area for about 10 years. VoiceGenie is a follow-up to a solution we had previously called BlueGenie. It is much more capable to be used when music is playing. I’m a runner. What I found is that when I am running, I am always pulling out my phone to do things, even answer the phone or change a song. The user experience is kind of tough on small headset devices. The buttons are small and you typically use them without looking at them. VoiceGenie feels a lot like having an Amazon Echo in your ear so you can just speak to do what you need to do without ever taking the phone out.
Why are you using Alexa when you have your own speech engine?
Mozer: We provide access to both. If you say “VoiceGenie,” you can control the headset or the mobile device handset. If you say, “Alexa” you can get access to the ten thousand skills on Alexa. We call it, “Alexa on the go” because it doesn’t require a WiFi connection. You can go out on a run and never have to pull your phone out. I can access things with VoiceGenie that assistants can’t do, like control the volume on my headset or access features on the phone through Bluetooth. I now have access to any of those approaches.
How do you connect with Alexa?
Mozer: We have a little voice genie app and the user just needs to login to their Amazon account. Without that app you can still control the headset and handset with VoiceGenie, you just wouldn’t have Alexa on the go.
I saw in a CNET article that you are building iOS and Android apps to enable cloud access to Alexa on the go. How will that be different that something like Swift or Lexi?
Mozer: VoiceGenie is done through a Bluetooth headset and is completely hands free. My guess is that the other apps haven’t done a recognizer that works on Bluetooth chipsets. For example, on a Qualcomm CSR chip we run a recognizer and music decoder together because it is a tiny little system so you need to intertwine the voice recognition with the music player to use both at the same time. I assume that the other apps run on the phone and write into an Alexa API, but that is a small part of what we’re doing. It is the integration with the Bluetooth device that makes it magical. We are actually putting intelligence on that device. Otherwise you wouldn’t be able to get that Amazon Echo experience where you just talk and it responds without having to touch anything, even when music plays.
That same article seems to indicate you can facilitate multi-voice AI interaction for Cortana, Siri, Alexa and Google. Is that true?
Mozer: We can do wake-up words for any engine we like, but we have decided to do it for Alexa first. We can also call up the voice assistant application on the phone. We aren’t doing Siri wake-up but have a VoiceGenie command to access Siri on Apple or Google [Assistant] for Android. We can access any application on the device including the embedded voice assistant. We’ve chosen Alexa for the direct cloud access.
Why did you choose Alexa over the other options?
Mozer: Alexa is really good at music. We thought one of the primary uses would be music. Amazon is also a cool company and easy to work with. On top of that, there are so many skills. We don’t have to work directly with Fitbit to get access to that device. We can do it through Alexa.
It is really nice that you can control everything in your house from your Amazon Echo. However, you can’t walk around with it. With VoiceGenie you can walk around and access everything from your hearable device wherever you are. That is important.
There a couple of schools of thought about how voice interfaces will develop. Some are betting that microphones will be embedded in the devices around us which will always be connected to the cloud while others are assuming the microphones will always be with us and personal such as on the mobile phone or in bluetooth headphones connected to the phones. What balance of these two modalities or others do you expect?
Mozer: I think both will peacefully coexist. In the long run, microphones embedded close to us, in our ears or in our clothes, will have a really special place because it will be a more private experience. We will see a popularization of embedded microphones near or in our ears in the future. They will become more and more invisible. We will want assistants with us everywhere we go and we will want them to have more senses like vision to help us in our daily lives.
When I go to the trade show in the future I might have an embedded assistant that recognizes someone and in my ear the assistant will tell me who they are and the last time we met. There are many applications like that.
Do you see something like the Amazon Echo as just a stepping stone between visual user interfaces and personalized, in-ear interfaces?
Mozer: Well, everything in a way is a stepping stone to something else. But, I see the Echo as a huge step forward. It definitely has a place long-term, although it will certainly evolve. Echo is basically a music player with a lot of intelligence in it. As a stand alone music player that is not going away. Any or all of these devices in the home can add more and more intelligence to help us do a lot of things, some will become more specialized.
Adding a device with microphones in every room becomes useful. When you add 10 devices in every room the benefit becomes marginal, and if there are multiple assistants in the different devices, things could get very confusing with more “false firing” and devices speaking when they aren’t spoken to. There are some really cool things that haven’t happened yet, but could where these devices talk to each other, compare notes and make better decisions by having multiple devices in the same room.
I will say that our intelligent products also need to add more sensors to make them smarter. A microphone is a great start, but they need a camera and other capabilities. The idea is to make them intelligent because they are aware. For example, Sensory is in a lot of homes listening for wake words. Now we can listen for smoke alarms going off and warn the homeowner by calling them. It’s really neat.
It often seems like AI is widely used for speech recognition and understanding, but is rarely used for accessing delivering the content behind it back to the user. All of the content delivery seems to be rules based. Do you agree?
Mozer: It’s a good comment. AI can be defined in so many ways. It seems like the conventional way people talk about AI is doing deep neural nets or machine learning. For speech recognition, deep learning is definitely the method of choice. For vision, it is absolutely going on as well. After that, you are right – the responses are often programmed. Even then, the majority of the things out there aren’t using deep learning for dialogue processing. There are a bunch of linguists sitting around building grammars and statistics on what people will say and doing rules based recognition. There aren’t a whole lot of companies with sufficient data to do it right with deep learning NLU. Google does, but not a lot of companies have their resources or data.
Sensory doesn’t have sufficient data to do everything. We are able to get sufficient data in certain domains. Sensory is very domain specific because of data availability. That stems from being an embedded company where our customers don’t collect the data from our recognizers. We do have AppLock by Sensory. It is the best rated biometric solution in the Google Play store. We’ve had hundreds of thousands of downloads and are getting more than a terabyte of data on people’s faces and background noises each week. It’s really been an amazing source of data.






